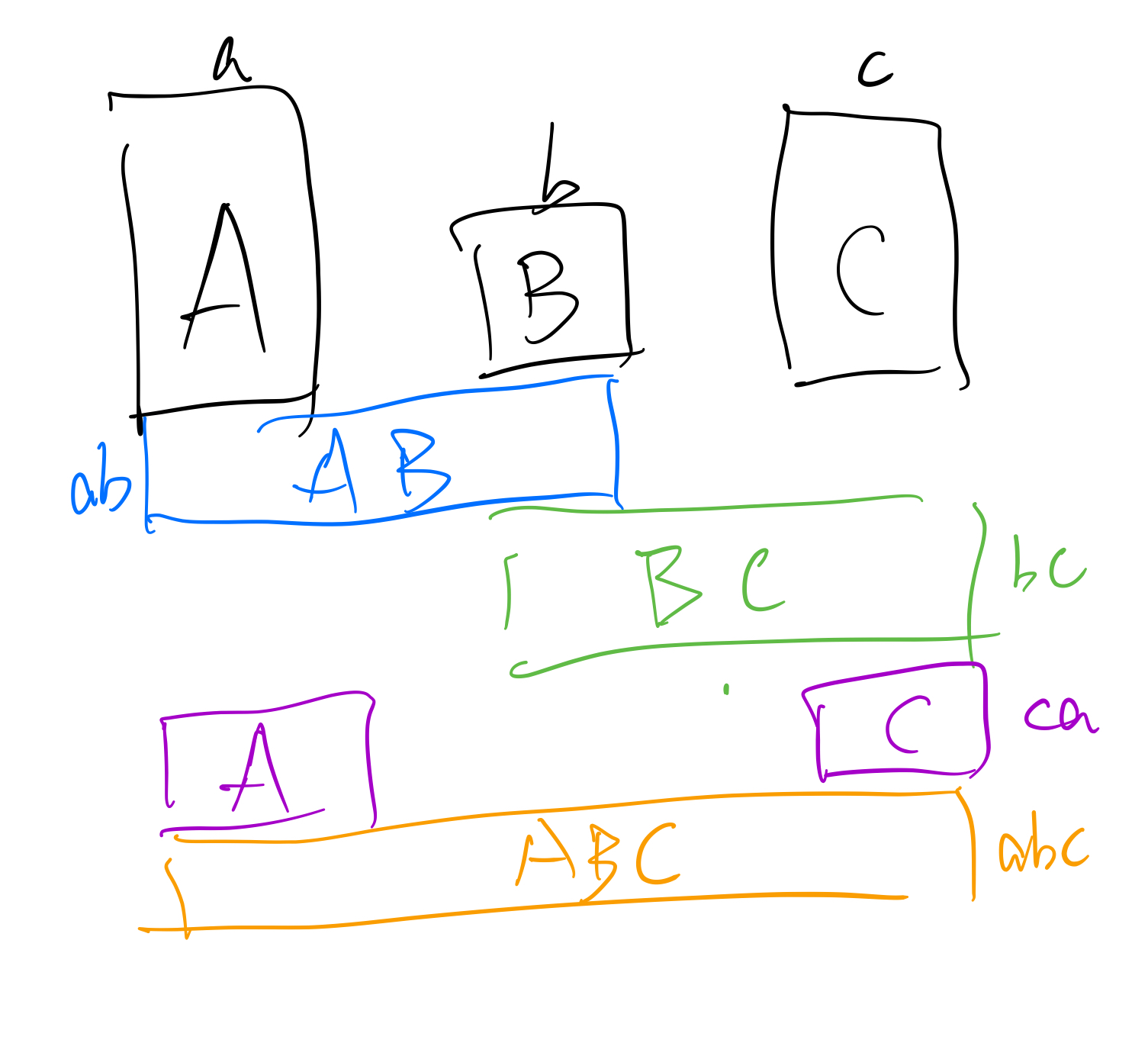
intmain(){ init(); int t; cin>>t; while(t-->0){ int v[3]; scanf("%d %d %d",v,v+1,v+2); int gab= gcd(v[0],v[1]); int gbc= gcd(v[1],v[2]); int gca= gcd(v[2],v[0]); int gabc= gcd(gab,v[2]);
// 计算每一个的仅有的部分 /*0*/ll a = yzcnt[v[0]] - yzcnt[gab] - yzcnt[gca] + yzcnt[gabc]; /*1*/ll b = yzcnt[v[1]] - yzcnt[gbc] - yzcnt[gab] + yzcnt[gabc]; /*2*/ll c = yzcnt[v[2]] - yzcnt[gca] - yzcnt[gbc] + yzcnt[gabc]; /*3*/ll ab = yzcnt[gab] - yzcnt[gabc]; /*4*/ll bc = yzcnt[gbc] - yzcnt[gabc]; /*5*/ll ca = yzcnt[gca] - yzcnt[gabc]; /*6*/ll abc = yzcnt[gabc];
intmain(){ init(); int t; cin>>t; while(t-->0){ int v[3]; scanf("%d %d %d",v,v+1,v+2); int gab= gcd(v[0],v[1]); int gbc= gcd(v[1],v[2]); int gca= gcd(v[2],v[0]); int gabc= gcd(gab,v[2]);
// 计算每一个的仅有的部分 /*0*/ll a = yzcnt[v[0]] - yzcnt[gab] - yzcnt[gca] + yzcnt[gabc]; /*1*/ll b = yzcnt[v[1]] - yzcnt[gbc] - yzcnt[gab] + yzcnt[gabc]; /*2*/ll c = yzcnt[v[2]] - yzcnt[gca] - yzcnt[gbc] + yzcnt[gabc]; /*3*/ll ab = yzcnt[gab] - yzcnt[gabc]; /*4*/ll bc = yzcnt[gbc] - yzcnt[gabc]; /*5*/ll ca = yzcnt[gca] - yzcnt[gabc]; /*6*/ll abc = yzcnt[gabc];
/* construct: vertexsize * auto tarjan = new Tarjan(vertex_size) * * addpath // 1<=from_vertex,to_vertex<= vertex_size * tarjan.addpath(from_vertex,to_vertex) * * prepare an result array,and work * int res[vertex_size+1]; * tarjan.work(res); * * return: * res[vertex_id] ===== after_tarjan_vertex_group_id */ classTarjan{ int *low;// lowest node int *dfn;// deep first node int *stk;// stack bool *instk; bool *visited;