Atcoder abc275
https://atcoder.jp/contests/abc275/tasks
G - Infinite Knapsack
n种物品, 每种无限多个
第i种, 重ai,体积bi,价值ci
f(X) = 总重量<=X,总体积<=X的最大价值
可证明 lim_{x->infty}f(X)/X 的极限存在, 求极限
范围
n 2e5
ai,bi,ci [1e8,1e9]
2s
1024mb
我的思路
感觉就一个很数学的题
考虑3元组, (a,b,c) 若 a >= b, 等价于a个(a/a,b/a,c/a)
若 a < b, 等价于a个(a/b,b/b,c/b)
于是分成两种
$(1,p\le1,c_0),p=b_0/a_0$
$(q\le1,1,c_1),q=a_0/b_0$
而实际上未来增长只会是 这两种按一个比例的和
$(t_0,pt_0,c_0t_0) + (qt_1,t_1,c_1t_1)$
$t_0 + qt_1 = pt_0+t_1 $
$t_0 = t_1 (1-q)/(1-p)$
$c_{0,1} = (c_0t_0 + c_1t_1)/(t_0 + qt_1)$
$= (c_0(1-q)/(1-p) + c_1)/((1-q)/(1-p)+ q)$
$= (c_0/(1-p)+c_1/(1-q))/(1/(1-p)+q/(1-q))$
$ans=\max(c_0,c_1,(c_0(1-q)+ (1-p)c_1)/((1-q)+ (1-p)q))$
问题是两两计算的话 为n^2
稍微改一下
$1,p < 1,c_0$
$1,q > 1,c_1$
$pt_0+qt_0=t_0+t_1$其中$t_0,t_1 > 0$ 即$t_0 = t_1 \frac{q-1}{1-p}$
$c_{0,1}=\frac{c_0t_0+c_1t_1}{t_0+t_1}$
$= \frac{c_0\frac{q-1}{1-p}+c_1}{\frac{q-1}{1-p}+1}$
$= \frac{\frac{c_0}{1-p}-\frac{c_1}{1-q}}{\frac{1}{1-p}-\frac{1}{1-q}}$
也就是 $(\frac{1}{1-\frac{b_i}{a_i}},\frac{\frac{c_i}{a_i}}{1-\frac{b_i}{a_i}})$ 这些点之间的最大斜率
n个点之间 找最大斜率
但注意到的是 是由第4向限和第1向限的点, 并不是两两之间, (因为两两之间的话 相当于$t <0)
直接考虑 分别两坨点的凸包
双指针???? 不会了
题解
类似的, 变成达到价值为1, 需要的 max(weight,volume) 的最小值,每个可取非负实数个
所以考虑(A/C,B/C,C/C)
平面上画(A’,B’)
那么其实两点之间的线段 就是两点可以变成的点(加权平均数)
一个点对应的答案是max(x,y)
而一条线段MN 和 y=x 的交点O, 有性质MN上的点P, 在MO一侧和在NO一侧, 总有一个坐标大于$O_x,O_y$
所以就是求所有点与$x,y$的交
对所有点求凸包, 显然任意两点的线段在凸包中(凸包的性质)
因此求凸包上与y=x的交点,即可
代码
https://atcoder.jp/contests/abc275/submissions/36129413
1 |
|
Ex - Monster
给定长N数组A
每次选区间 [l..r], 花费代价max(B[l..r]), 让A[l..r]-=1
让所有$A[i] <= 0$ 的最小代价和
范围
N 1e5
ai,bi [1,1e9]
2s
1024mb
我的思路
显然每次 全区间减一 是一个方案, 所以上限是 max(Bi) * max(Ai)
那么一个操作方案, 交换顺序 也会有同样的最终的A和代价, 所以顺序不影响 结果和代价
不会有 相邻的操作
[a...b][b+1..c]
这样的代价是max(B[a..b])+max(B[b+1..c]), 而直接B[a..c] 代价=max(B[a..c])=max(max(B[a..b]),max(B[b+1..c]))
A[i] >= A[i+1], B[i] >= B[i+1], 那么必定每次选i的时候能白带上i+1, 因为至少A[i]次操作在A[i]上,且选的值>=B[i]>=B[i+1], 所以如果没有选i+1,那么带上i+1 不会更差
因此 这种i+1 直接干掉, A[i]>=A[i-1]且B[i]>=B[i-1]同理
因此数组变成 若 A[i] > A[i+1] 则B[i] < B[i+1]
简而言之, 若A比相邻的大于, 则B比相邻的小于
也就是 A的下降 对应B的上升, A的上升对应B的下降
感觉对区间的A最大 尽心贪心? 选它大于相邻最小次B?
但似乎也不对, 下面这样的话,可能一次把所有大的-1 比单独的每个处理更优
1 | A: 大小大小大小大小大小大小大小 |
考虑
1 | [l...m][m+1..r] |
切分
那么对于m来说 至少在m上操作了A[m]次
m+1来说 至少在m+1上操作了A[m+1]次
那么这些次之间顺序不重要, 假设 分别排序为vec0,vec1
那么每次合并两个, 就是 左右中大的那个, 考虑从大到小匹配, 每次有 小的代价的盈余
= 左+右-盈余
问题是, 这样左右状态那是 [总代价, vec], 1e5 的1e5次方?
再来
1 | dp[i] = [总代价, vec] |
上面有不会有相邻区间的选择
那么考虑dp[i+1] , 从状态转移, 就是
新的vec最大的a[i+1]个需要大于等于B[i]
所以 一共要最大A[i]个, 然后
对于所有i, 前A[i]个 大于等于B[i]
就没了?
其实并不对, 这里 应该是至少a[i+1]个, 然后每个需要>=Bi, 也就是当个数不变的话, 超过a[i+1]的也会被影响
1 | Al -> Ar 单调递减 |
初始是vecl 结束是vecr
显然 A[r] <= len(vecr) <= len(vecl)
vecr[i] = max(vecl[i],B[r]) 因为中间都比B[r]小 不影响结果
但是中间变化时 可能有 大于len(vecr)的 改变 vec的值
感觉也不行
考虑
1 | A: 1e9 1 1e9 1 1e9 1 1e9 1 |
这样的话, 需要 约 (NAi)次, 所以次数/和 光是这个维度都过于大
问题在于 一个局部的峰 肯定是单独处理峰更好, 而非局部的多个峰同时处理可能优于单个处理
而两个峰决定一起处理, 相当于 把 两个中低的高度 等高的全部合并成一个, 代价为 最低的B[i]
1 | x |
就是找不出局部性啊…
题解
如果选的[l..r]的代价为b, 而[l-1..r] 或者[l..r+1]的代价依然是b, 那么就考虑更长的, 显然左右扩展的距离互不影响
也就有对于任何选的区间[l..r],
B[l-1] > 所有[l..r]
B[r+1] > 所有[l..r]
为了方便边界,可以假设两头B无限大,而A为0
这样的话, 考虑区间最大值在i取到, 那么对应的左右[li,ri]就唯一了!!!!!, 根据Bi来决定
所以只可能有 n种可选区间
考虑构建二叉树, 以最大的Bi为根(那么它其实就是对应(1,n), 左子树就是左边最大的为根, 右子树就是右边最大的为根,而区间就从i划分开了
有性质 树上 节点比子节点大, 在当前节点和子树中只有当前节点覆盖了i
所以 在树上 设计DP
dp[i][j] = 第 Bi对应的区间 [li..ri], A[li..ri] -=j 的答案(只考虑[li..ri]
答案=dp[最大Bi的下标][0]
如果区间长度为1即li==ri, 有 $dp[i][j]= \begin{cases} (A_i-j)B_i & (0\leq j\leq A_i) \\ 0 & (A_i\leq j), \end{cases}$
否则考虑 对当前节点使用$k(\ge \max(A_i-j,0))$次(至少覆盖当前, 而对左右来讲可能额外覆盖), 然后就是左右子树的递归问题
$dp[i][j]=\displaystyle\min_{\max(A_i-j,0)\leq k} \lbrace kB_i+ dp[\mathrm{child}_ l][j+k]+dp[\mathrm{child}_ r][j+k]\rbrace.$
而随着$k+=1$ 增量$B_i+(dp[x][j+k+1]-dp[x][j+k])+(dp[y][j+k+1]-dp[y][j+k])$ 在单调递增
归纳法: dp[i][] 随着j 单调递减, 且增量([j+1]-[j])单调递增(下凸函数)
存在一个$k$和$k+1$在正负交界的位置
再换句话说, dp[i][j] 不影响min中的函数的’形状’, 而只是影响k的范围和 对函数的平移, 而取min就是对最小值的平移
设是$j_{\min}$让$dp[\mathrm{child}_ l][j]+dp[\mathrm{child}_ r][j]$取到下凸函数的最小值
那么就是看$j+k = j_{\min} \ge A_i$能不能取到, 于是
$dp[i][j]=\begin{cases} (j_{\min}-j)B_i+ dp[x][j_{\min}]+dp[y][j_{\min}], j\le j_{\min} \\ dp[i][j]=dp[x][j]+dp[y][j], j\ge j_{\min}\end{cases}$
多线段优化(Polyline optimization
上面这样搞还是需要 每个树上的点是一个左边一次函数,右边多点的下凸, 还是O(NAi)的,而且还有左右凸函数合并的过程
考虑j的取值, 显然 j >= max(A[l..r]) 时, $dp[i][j]=0$, 然而$A_i$很大
考虑维护斜率(斜率变化点) 来维护,这样最多N个点, 还是$N^2$
而实际上 每个点 等于左右儿子的合并, 如果每次轻儿子向重儿子合并, 那么就只用操作$O(n log n)$个点
而如果能把上面公式转化成合并前后是不动点, 那么就可以实现了, 现在问题是有什么办法
让 dp[child l][...] 和 dp[child r][...] 的合并前后是不动点
先说函数加和, 如果记录的是相邻增量的差, 那么就可以简单的合并!
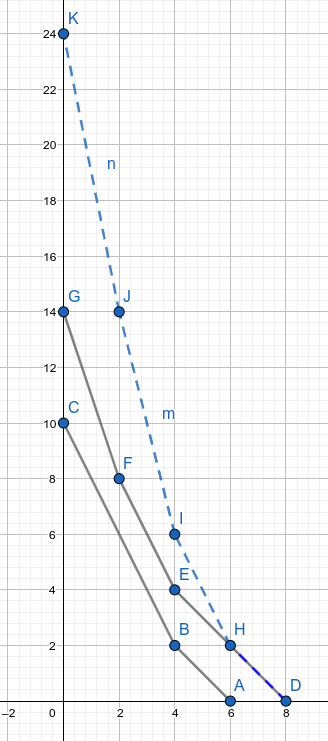
如图, 蓝色虚线是两个黑色的加和
其实从数学的角度讲, 两个按位置加和 去做任意与加满足分配的运算比如导数 都可以拆分
而直接记录点, 斜率的问题就是, 还需要改, 比如F变成J
而如果是记录前后斜率差, F变成J是不会变化的, 只有B+E=I这种共点需要加一下, 所以把小的向大的合并,只需要做小的次数
不妨记左右儿子合并后的为$f$
而对于 dp公式
$dp[i][j]=\begin{cases} (j_{\min}-j)B_i+ f[i][j_{\min}], j\le j_{\min} \\ dp[i][j]=f[i][j], j\ge j_{\min}\end{cases}$
也就是需要把左边一段变成斜率为$-B_i$, 这可以直接从左向右枚举
因为如果枚举到了要么停止要么删除,而停止最多一次,删除的点不超过加入的点
所以总的均摊的左侧枚举就是O(N)
因此从数据结构上
记录 ((点0的y值,斜率), map[点]=斜率差)
而实际上, 点0的具体值只有最后才需要, 所以可以全部记录斜率, 只是map[0] 表示的是直接的斜率而不是斜率差
代码
https://atcoder.jp/contests/abc275/submissions/36145016
1 |
|
总结
G
计算几何 方向对了, 但是题意转化不尽人意, 搞出了需要找斜率的问题, 而题解里的转化成交点就显然很多了
Ex
考虑区间性质而不是相邻的性质, 这样一下就降低到只有n个区间,还是靠区间最大值划分的, 感觉 似乎几次区间最大值都是类似的建立树,应该建立条件反射了
然后就是凸函数一类的斜率维护和函数合并,不动点的知识了
感觉这次的Ex虽然是个 铜牌3210分的题, 但是对我来说 都是之前补abc学过的知识点了没新知识点, 而我还是自己没搞出来, 甚至卡在第一步了, 哎